

PythonでExcelのような表形式のデータを扱いたいときに便利なのがPandasと呼ばれるPythonライブラリ。
Pandasのデータ構造にはSeries型と呼ばれる1次元のデータと、DataFrame型と呼ばれる2次元のデータ2つがあります。
2次元のデータ構造は、列と行、縦と横と2方向にデータが分かれた形だと思ってください。Excelやスプレッドシートの表形式です。
Pandasを用いてDataFrameの操作が可能になると、今まで生徒の試験点数など複数のデータをエクセルで集計し、平均などを出していたものをPythonでまとめて出せるようになります。
もしこれから、機械学習やデータ分析を学習したいと考えているのであれば、必須のスキルです。
今回はそんなPandasでDataFrameの作成をどんな風に行うのか、基本操作の部分をわかりやすく解説していきます。
Pandas入門:DataFrameの構造を理解する

DataFrameの作成を行う前に、まずはDataFrameの構造を説明しておきます。
前回解説したSeries型と比較して行くことで1次元と2次元の違いも理解してもらえると思います。
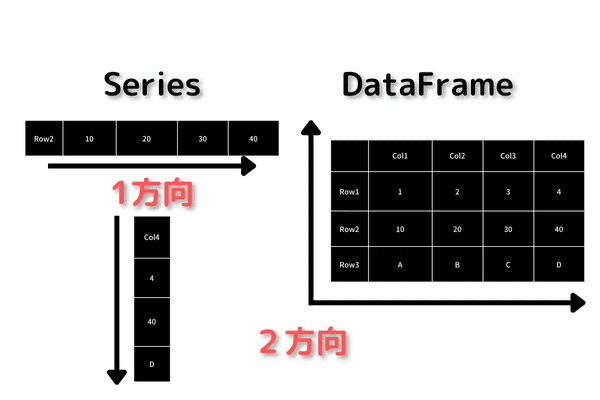
DataFrame型はExcelやスプレッドシートのような表敬式のデータです。縦と横、列と行、カラムやインデックスといった2方向にデータが並んでいるようなデータ構造のことです。
SeriesはDataFrameから縦か横の1方向にデータを切り取った形式をしています。
また、列名のことをカラム名と呼び、行名のことをインデックスと呼びます。指定しないと、0,1,2,3が初期値となるので、必要に応じて自分で名前を設定します。
では早速、DataFrameを作成する方法を解説していきましょう。
DataFrameの作成方法
import pandas as pd今まで同様に、インポートから行っていきます。
DataFrameの作成には、「pd.DataFrame()」を使います。引数(括弧内)には「data, index, columnse, dtype copy」を取ります。dataに辞書を格納したり、ndarrayを格納することでDataFrameの作成ができます。
indexやcolumnsにはリストやarrayを入れてあげることで、インデックス名、カラム名をそれぞれ指定してあげることもできます。何も指定しないと初期値(0,1,2,3・・・・)となります。
今回は様々な作成方法の中から、以下の方法を解説していきます。
- 辞書から作成
- 辞書のリストから作成
- ネスト構造の辞書から作成
- ndarrayから作成
- csvファイルから読み込み
- Excelから読み込み
DataFrameの作成①:辞書からの作成
import pandas as pd
#辞書型からの作成
pd.DataFrame(data={
"A":['エー','apple'],
"B":['ビー','bingo'],
"C":['シー','crypto'],
"D":['デー','developper'],
})
**出力結果**
A B C D
0 エー ビー シー デー
1 apple bingo crypto developperpd.DataFrame(data=○○) ○○に辞書を格納してあげると、辞書で指定したKey値がカラム名に、Value値が各データに反映されたDataFrameが作成されます。
辞書から作成すると、カラム名を指定しなくてもいいので便利です。(変更したい場合には指定してもいいです。)
インデックス名は別途指定して上げる必要があります。
#インデックス名を指定してあげる
pd.DataFrame(data={
"A":['エー','apple'],
"B":['ビー','bingo'],
"C":['シー','crypto'],
"D":['デー','developper'],
},index=['1列目','2列目'])
**出力結果**
A B C D
1列目 エー ビー シー デー
2列目 apple bingo crypto developperちなみに指定するときは、直接引数の中に入れてあげてもいいですが、変数に格納してから、引数に指定する方法でも作成できます。
#辞書を作成
dict = {
"A":['エー','apple'],
"B":['ビー','bingo'],
"C":['シー','crypto'],
"D":['デー','developper'],
}
#インデックス名のリストを作成
index_name = ['1列目','2列目']
#データフレームを作成
pd.DataFrame(data = dict,index = index_name)**出力結果**
A B C D
1列目 エー ビー シー デー
2列目 apple bingo crypto developper注意点として、指定するインデックスの数は、作成する行数と合わせる必要があります。辞書から作成する場合は、Value値の数が行数となります。
もしも、行数が2なのに対して、インデックス名を3つ指定していたり、辞書のValue値が全部2つずつなのに、一つだけ3つ格納していたら、DataFrameは上手に作成できませんので注意が必要です。
#一つでもValue値の個数が違うとエラーになる
pd.DataFrame(data={
"A":['エー','apple'],
"B":['ビー','bingo'],
"C":['シー','crypto'],
"D":['デー','developper','diamond'],
})
ValueError: All arrays must be of the same lengthDataFrameの作成②:辞書のリストから作成
#辞書のリストから作成
dict_ls = [{'a':'apple','b':'bigo','c':'crocks'},
{'d':'diamond','c':'crypto','b':'book'},
{'a':'analytics','d':'doragon','e':'eight'}]
pd.DataFrame(dict_ls)
a b c d e
0 apple bigo crocks NaN NaN
1 NaN book crypto diamond NaN
2 analytics NaN NaN doragon eightDataFrameの作成2つ目は、辞書のリストからの作成です。
辞書からの作成では、value値の個数が異なるとエラーになっていましたが、辞書がリスト構造になっていると、Key値が等しい場合には値が格納され、該当がない場合には欠損値「NaN」が格納されたDataFrameが作成されます。
DataFrameの作成③:ネスト構造の辞書から作成
#ネスト構造の辞書から作成
dict_nest = {'1列目':{'1行目':'A1','2行目':'A2','3行目':'A3'},
'2列目':{'1行目':'B1','2行目':'B2','3行目':'B3'},
'3列目':{'1行目':'C1','2行目':'C2','3行目':'C3'}}
pd.DataFrame(dict_nest)
1列目 2列目 3列目
1行目 A1 B1 C1
2行目 A2 B2 C2
3行目 A3 B3 C3ネスト構造の辞書とは、辞書の中に辞書が入っている構造です。
ネスト構造の辞書からDataFrameを作成すると、インデックス名やカラム名を指定することなく、初期状態から反映してくれるので使い方によってはかなり便利です。
辞書型のリストと同じで、該当がない値には欠損値「NaN」が入ります。
#欠損値も表示される
dict_nest = {'1列目':{'2行目':'A2','3行目':'A3'},
'2列目':{'1行目':'B1','2行目':'B2'},
'3列目':{'1行目':'C1','2行目':'C2',}}
pd.DataFrame(dict_nest).sort_index()
1列目 2列目 3列目
1行目 NaN B1 C1
2行目 A2 B2 C2
3行目 A3 NaN NaNpd.DataFrame().sort_index() は詳しくは次回解説しますが、一行目が下に来てしまうため、インデックスを基準に並び替えを行いました。
DataFrameの作成④:ndarrayから作成
#numpyから作成したndarrayから作成
import numpy as np
ndarray= np.array([[1,2,3,4],
[10,20,30,40],
["A","B","C","D"]])
print(pd.DataFrame(data2))
print(pd.DataFrame(data2).T)
**出力結果**
0 1 2 3
0 1 2 3 4
1 10 20 30 40
2 A B C D
0 1 2
0 1 10 A
1 2 20 B
2 3 30 C
3 4 40 Dndarrayとは、Pandasの中身に使われているNumPyによって作成される、複数のリストをリストの中に入れられるデータ構造のことです。
NumPyも、Pandasと同様、npと簡略化して使われるのが慣習です。
ndarrayは、np.array() で作成することができます。
DataFrameの作成⑤:CSVファイルからの読み込み(df.read_csv)
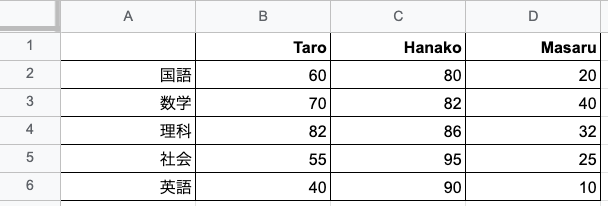
#CSVファイルからDataFrameを作成
pd.read_csv('./read_csv.csv')
**出力結果**
Unnamed: 0 Taro Hanako Masaru
0 国語 60.0 80.0 20.0
1 数学 70.0 82.0 40.0
2 理科 82.0 86.0 32.0
3 社会 55.0 95.0 25.0
4 英語 40.0 90.0 10.0表計算ソフトですでに作成してあるデータをPandasに読み込んでDataFrameを作成することもできます。
df.read_csv('作業中のディレクトリから見た相対パス') で作成できます。作業中のディレクトリと同じ層にあるファイルであれば、「pd.read_csv('./read_csv.csv')」で作成できますし、作業ディレクトリにあるフォルダの中にある場合は、「pd.read_csv('./フォルダ1/read_csv.csv')」で作成します。
CSVファイル以外にも、Excelや、JSONファイルからも作成できますので、必要な時はご自身で調べてもらえたらと思います。
また、CSVファイルからの読み込みなどは、膨大な量のデータを読み込むことが多くなってくるので、以下で説明する基本操作や次回以降に解説する予定のデータ整形のスキルも必要になってくるので、少しずつスキルを磨いていきましょう。
DataFrameの基本操作
DataFrameを作成したあとに、インデックス名やカラム名を変更したり、値を変更したりする時の操作についても一応触れておきます。
場所を指定して、値を変更するような流れです。
インデックス名の確認
import pandas as pd
student_point = {
'Taro':{'国語':60,'数学':70,'理科':82,'社会':55,'英語':40},
'Hanako':{'国語':80,'数学':82,'理科':86,'社会':95,'英語':90},
'Masaru':{'国語':20,'数学':40,'理科':32,'社会':25,'英語':10},
}
df = pd.DataFrame(student_point)
df
----
df.index**出力結果**
Taro Hanako Masaru
国語 60 80 20
数学 70 82 40
理科 82 86 32
社会 55 95 25
英語 40 90 10
-----
Index(['国語', '数学', '理科', '社会', '英語'], dtype='object')インデックス名を確認したい時や、変更したいときには df.indexを使います。
#インデックス名の変更
df.index = ['こくご','すうがく', 'りか', 'しゃかい', 'えいご']
df**出力結果**
Taro Hanako Masaru
こくご 60 80 20
すうがく 70 82 40
りか 82 86 32
しゃかい 55 95 25
えいご 40 90 10インデックス名を、df.index で選択してから、新しいインデックス名を指定して上げることでインデックス名の変更が可能です。
カラム名の確認、変更
#カラム名の確認
df.columns**出力結果**
Index(['Taro', 'Hanako', 'Masaru'], dtype='object')カラム名の確認には df.columns を使います。
変更したいときはインデックス名と同じで、新しいカラム名のリストを入れてあげればOKです。
#カラム名の変更
df.columns = ['太郎','花子','勝']
df**出力結果**
太郎 花子 勝
こくご 60 80 20
すうがく 70 82 40
りか 82 86 32
しゃかい 55 95 25
えいご 40 90 10Taro、Hanako、Masaruとローマ字表記だったものを、漢字表記に変更してみました。
DataFrameのデータ変更
student_point = {
'Taro':{'国語':60,'数学':70,'理科':82,'社会':55,'英語':40},
'Hanako':{'国語':80,'数学':82,'理科':86,'社会':95,'英語':90},
'Masaru':{'国語':20,'数学':40,'理科':32,'社会':25,'英語':10},
}
df = pd.DataFrame(student_point)
#データの抽出
df['Taro']
**出力結果**
国語 60
数学 70
理科 82
社会 55
英語 40
Name: Taro, dtype: int64
DataFrameのデータを変更するには、場所を指定してあげてから変更をかけてあげる必要がある為、まずは場所の選択のしかたを覚えていきましょう。他の記事をみると、抽出とか検索とかっていう操作に関する解説です。。
一旦インデックスとカラムの変更前の状態に戻してあげて、Taroの列だけを取り出してみました。
列を取り出すときは、df['列名'] で取り出すことができます。
取り出したデータは、Series型で取り出されているのですが、いわゆるTaro列の場所を指定している状態なので、以下のように新しいリストを格納してあげることで値を変更することができます。
#値の変更
df['Taro'] = [60,60,60,60,60]
df**出力結果**
Taro Hanako Masaru
国語 60 80 20
数学 60 82 40
理科 60 86 32
社会 60 95 25
英語 60 90 10一応わかりやすいように、Taro列を全部60点にしてみました。
列の中で1箇所の値だけを変更したいときは、Series型でのデータ変更を思い出してみて貰えばわかると思いますが、インデックス名(行名)を指定してあげることで、1箇所だけの変更もできます。
#1箇所だけ値を変更
df['Taro'] ['国語'] =100
df**出力結果**
Taro Hanako Masaru
国語 100 80 20
数学 60 82 40
理科 60 86 32
社会 60 95 25
英語 60 90 10df['列名']['行名'] = ’変更後の値' とすることで変更できました。
しかし、先に行を指定するとエラーになってしまうので注意が必要です。
行を選択して、一括して値を変更したいときには df.loc[]を使ってあげると便利です。
df.loc[]で場所指定 → 値変更
#df.loc['行','列']を使って場所の選択
df.loc['国語','Hanako']**出力結果**
80df.loc['行名','列名'] でExcelでいうところのセルを選択する事ができます。国語の行の、Hanako列、クロスするところの値は80ですよ〜っていうコードです。
複数行や、複数の列を選択するときには、「:(スライス)」を使います。「:」だけにすると、全部の行または列を選択してくれます。
#全部の行を選択
df.loc[ :,'Hanako']**出力結果**
Taro 60
Hanako 82
Masaru 40
Name: 数学, dtype: int64DataFrameのデータを変更するには、場所を指定してあげてから変更をかけてあげる必要がある為、まずは場所の選択のしかたを覚えていきましょう。他の記事をみると、抽出とか検索という操作を行う。
df.loc['数学',:]**出力結果**
Taro 70
Hanako 82
Masaru 40
Name: 数学, dtype: int64
「:」を使うと、全ての行や列をを選択する事が出来ます。コロンではなくスライスと呼ぶので覚えておきましょう。
行だけを選択して、列は全て選択したいときの:は省略することができます。
df.loc['数学']**出力結果**
Taro 70
Hanako 82
Masaru 40
Name: 数学, dtype: int64
今度は複数行を指定してみましょう。
#範囲を指定することも可能
df.loc['数学':'社会']**出力結果**
Taro Hanako Masaru
数学 60 82 40
理科 60 86 32
社会 60 95 25
数学の行から、社会の行までを選択したいときには、「'数学':'社会'」のように「:(スライス)」で区切り、数学の行と社会の行2行を取得したいときには、「'数学','社会'」と「,(カンマ)」で区切ってあげます。
DataFrameの値を変更する
#値の変更
df.loc['国語','Hanako'] = 85
df.loc[['数学','社会'],['Taro','Masaru']] =[[72,40],[55,27]]
df
**出力結果**
Taro Hanako Masaru
国語 100 85 20
数学 72 82 40
理科 60 86 32
社会 55 95 27
英語 60 90 10選択方法がわかったところで、実際に値を変更していきましょう。
df.loc['国語','Hanako'] = 85 で国語の行で、Hanakoの列の値は85です。とすることでもともとの値から変更することが可能です。
df.loc[['数学','社会'],['Taro','Masaru']] =[[72,40],[55,27]] と複数行を選択して、変更したい値をリストに入れてあげて変更してあげることもできます。
まとめ
Pandasは機械学習やデータ分析をするときには必須のスキルですが、他にもスクレイピング舌情報をCSVファイルに出力する際に、Pandasを使ってDataFrameにしてあげてから出力すると便利です。
今回の内容でDataFrameの作成と基本操作を習得しましたが、次回は、よりデータ分析をするための操作について解説していきます。
Excelでは、縦の列の合計をsum関数を使って縦の列の合計を計算したり、count関数を使ってデータの個数を計算したりできますが、Pandasでも簡単に平均や合計を出すことができます。
統計学的要素が次回から入ってくるので楽しみにしててください!
- DataFrameは表形式のデータ構造!縦と横の2方向にデータが格納されている形!
- DataFrameの作成方法は様々
- 辞書から作成
- 辞書のリストからの作成
- ネスト構造のリストから作成
- ndarrayから作成
- csvファイルからの作成
- DataFrameの基本操作
- df.index()
- df.columns()
- df.loc
独学に限界を感じたら・・・??
独学に限界を感じたときは、プログラミングスクールを利用するのが一つの手段です。
正直、高額なスクールもあったり、スクールには通ったけど結果が伴わない場合もありますが、最近は助成金がでたり、納得行かなければ全額返済のスクールもあるので、まずは一旦話だけでも聞いてみて、「あ、これならスクールに通ってみてもいいかも!」となった時に入校すればいいのです。
まずは無料相談や、詳細をサイトで確認することも大切です。
プログラミングを習得するのには目的が必要です
- 副業で少しでもプラスに稼ぎたい
- 自分のアイデアを生かして起業したい
- エンジニアに転職したい
また、プログラミングを習得することで転職や、副業、フリーランスなどの働き方に選択肢が広がりますので、将来に不安を抱えていたり、本当は今よりもやりたいことがある人は、キャリア相談を受けることで今の自分は何をすべきなのかが見えてきます。
キャリア相談については以下の記事でまとめていますので、ぜひご活用ください。
